I came across this paper several weeks ago when I was learning a tool called Airflow that helps with task orchestration, and I found the paper extremely practical and well written. It seems that for even small to medium sized machine learning systems, they’ll soon to be needing some sort of workflow management or scheduling tools for various jobs, including but not limited to model training and deployment. These systems also seem to be more brittle and more entangled. Having been worked both as a data scientist and a backend developer, I know it is not easy for most data scientist to deploy a model and maintain the codebase. The authors of this paper did an amazing job identifying the most common problems in machine learning systems and provided guidance on how to mitigate the risks. I would highly suggest everyone who’s working on machine learning projects read this paper. Yuo may find that the same problems are actually sitting in the codebase that you are working on.
Click here to read the original paper.
I will copy/paste the abstract of paper and list my keynotes.
Abstract
Machine learning offers a fantastically powerful toolkit for building useful complex prediction systems quickly. This paper argues it is dangerous to think of these quick wins as coming for free. Using the software engineering framework of technical debt, we find it is common to incur massive ongoing maintenance costs in real-world ML systems. We explore several ML-specific risk factors to account for in system design. These include boundary erosion, entanglement, hidden feedback loops, undeclared consumers, data dependencies, configuration issues, changes in the external world, and a variety of system-level anti-patterns.
Key Notes
Identified technical debts:
- Complex Models Erode Boundaries
- Entanglement
- Correction Cascades
- Undeclared Consumers
- Data Dependencies Cost More than Code Dependencies
- Unstable Data Dependencies
- Underutilized Data Dependencies
- Legacy Features
- Bundled Features
- ǫ-Features
- Correlated Features
- Static Analysis of Data Dependencies
- Feedback Loops
- Direct Feedback Loops
- Hidden Feedback Loops
- ML-System Anti-Patterns
- Glue Code
- Pipeline Jungles
- Dead Experimental Codepaths
- Abstraction Debt
- Common Smells
- Plain-Old-Data Type Smell
- Multiple-Language Smell
- Prototype Smell
- Configuration Debt
- Dealing with Changes in the External World
- Fixed Thresholds in Dynamic Systems
- Monitoring and Testing
- Prediction Bias
- Action Limits
- Up-Stream Producers
- Other Areas of ML-related Debt
- Data Testing Debt
- Reproducibility Debt
- Process Management Debt
- Cultural Debt
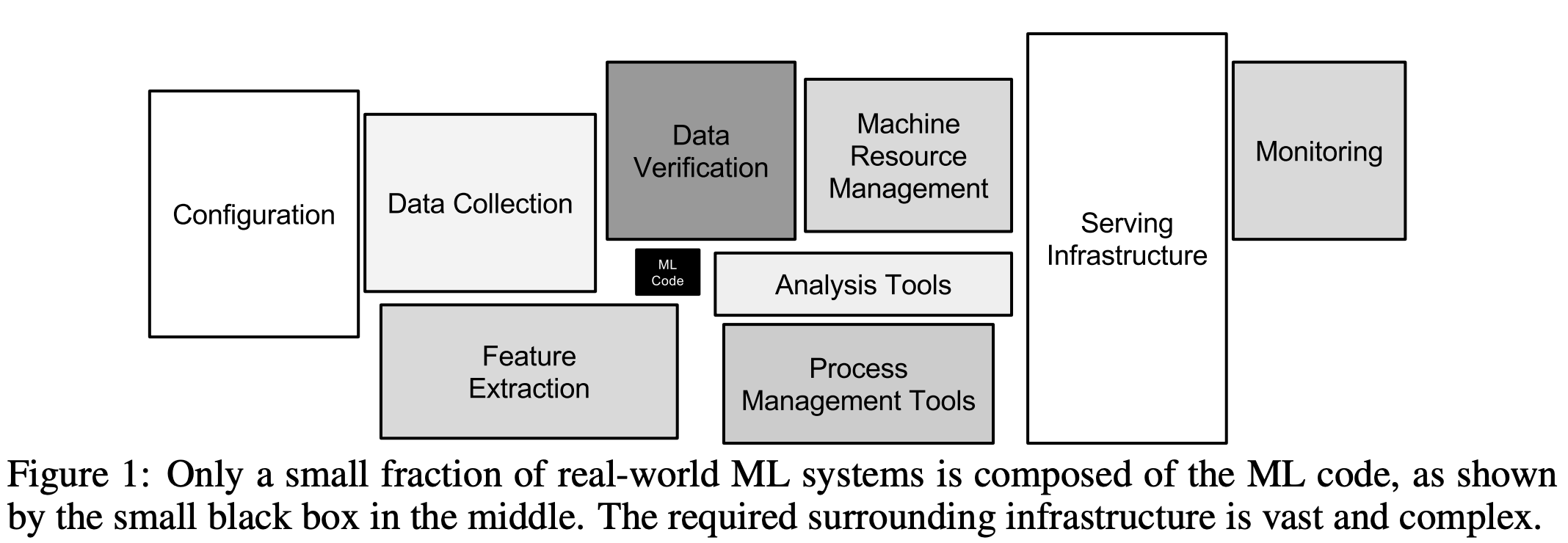
What we model is only a tiny portion of the overall machine learning system!
I think it is very hard to avoid the problems above as they don’t just require a single person or a single team’s input, there are external parties that can have a huge impact on how a machine learning system can be maintained, and sometimes it fits into the larger cultural theme. Having seen some of the tech debts above, I’ve realized how important it is to have a good infrastructure to support such systems and how critical it is to design a scalable system at the first place. After all, developers will come and go, but the system continues to run, there has to be a guideline that prevents individuals from complicating the already complicated machine learning system.