Calling AWS APIs in Python is made easy with the official boto3 SDK, if you want to use a service like AWS S3 programmatically, you can simply write:
1
s3_client = boto3.client('s3')
And then you can call S3 APIs like s3_client.get_object() and s3_client.list_objects().
But if you search the boto3 or botocore source code you can’t find a class like S3Client that’s created by boto3.client('s3'), the creation of a client that talks to S3 is behind the scene and involves some layers of complexity, one of which is the service model.
I will walk through what happens behind the scene of the following two lines of code, a AWS ECR API call.
1
2
ecr_client = boto3.client('ecr')
ecr_client.describe_repositories()
Creating Client
First of all, when you call boto3.client('ecr'), the first thing boto3 does is not actually creating an ECR client, but creating a global Session, source code of which can be found here. This Session will load a bunch of things upon creation, such as credentials (AWS_ACCESS_KEY, AWS_SECRET_KEY_ID), profiles, region, and a loader which is responsible for loading the service model. Then, it calls the .client() method on Session to generate the specific service client that you ask, i.e. ECR.
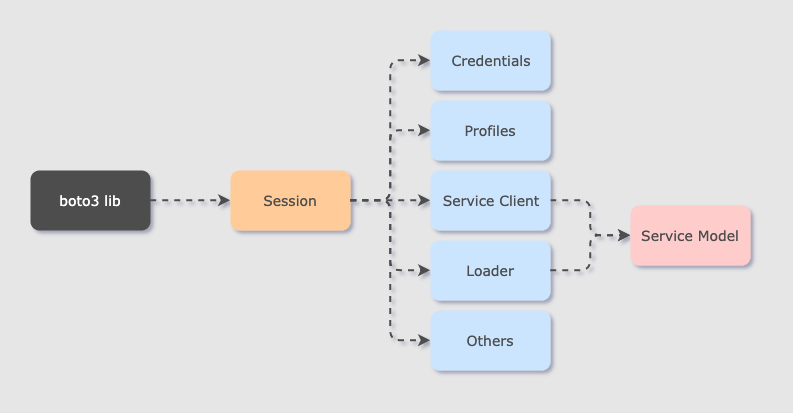
Loading Service Model
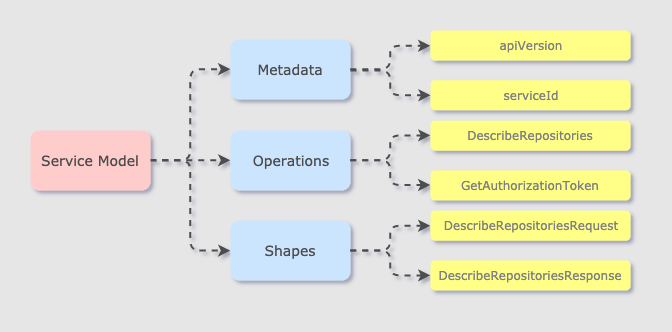
What is a service model? Below is the definition given by AWS on this page. Notice three terms: “generated classes”, “JSON models”, and “APIs”. So basically a service model defines a bunch of APIs like ecr_client.describe_repositories() living in a JSON file that generates classes when loaded.

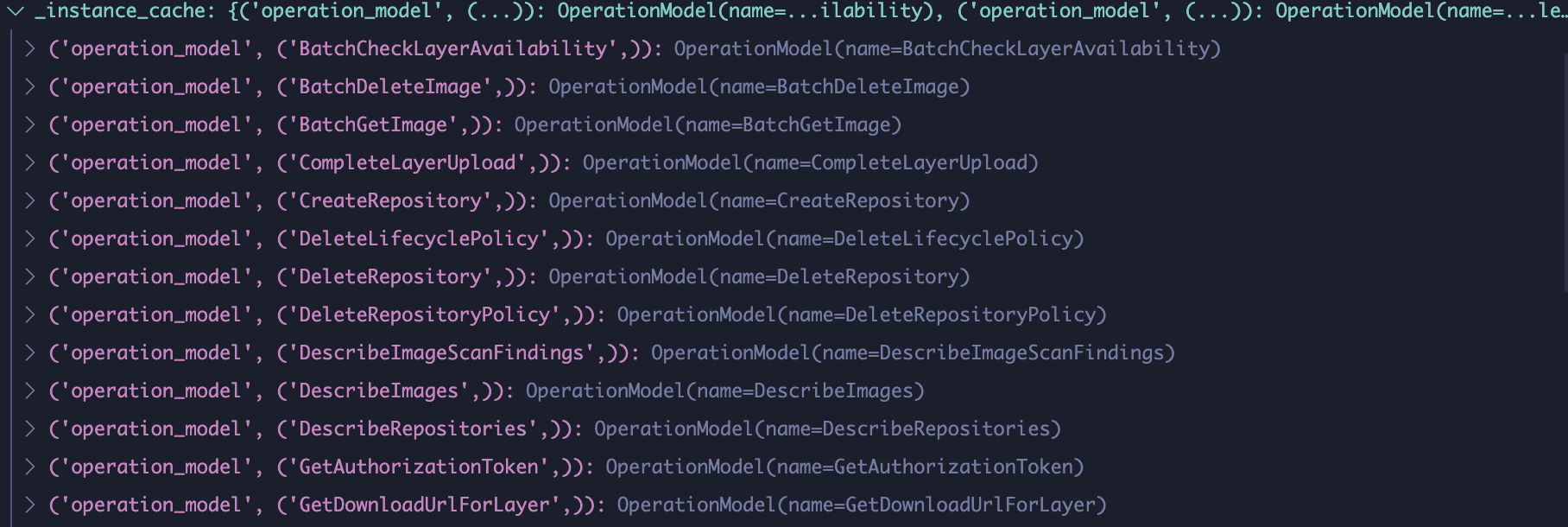
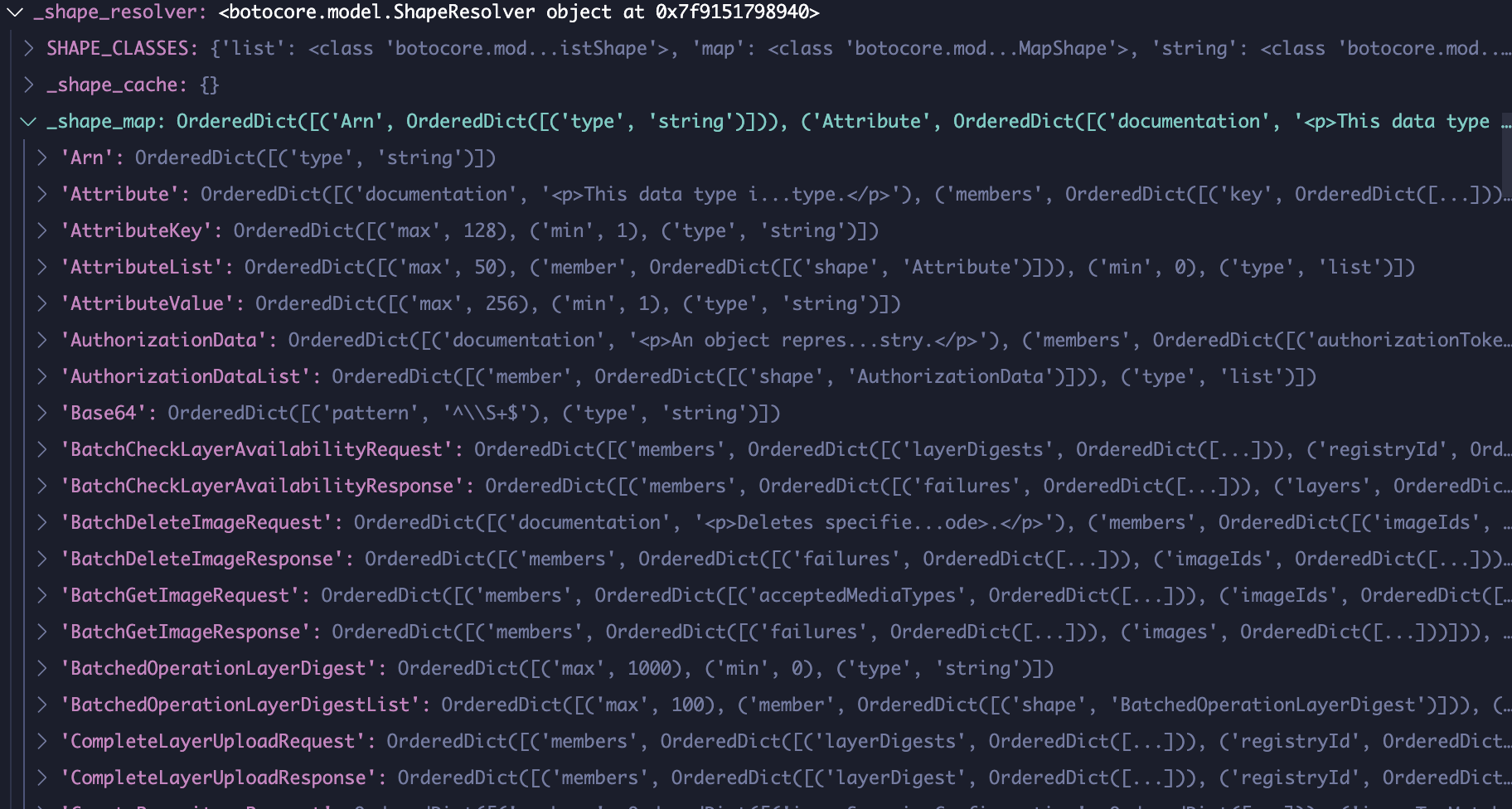
When loaded, service model creates certain API methods with three sub components: metadata, oprations, and shapes. Metadata lists details like the apiVersion and serviceId. Operations are actually APIs that you can call like DescribeRepositories. And shapes like DescribeRepositoriesRequest and DescribeRepositoriesResponse define the format and data types of API inputs, outputs, and all intermediate arguments.
You may wonder where is that JSON model? Well you can actually find it here or under botocore’s “./data” folder. It is such a long json file to read, so I recommend using some sort of json viewer to read, which gives a much better structured view. My favorite one is http://jsonviewer.stack.hu/.
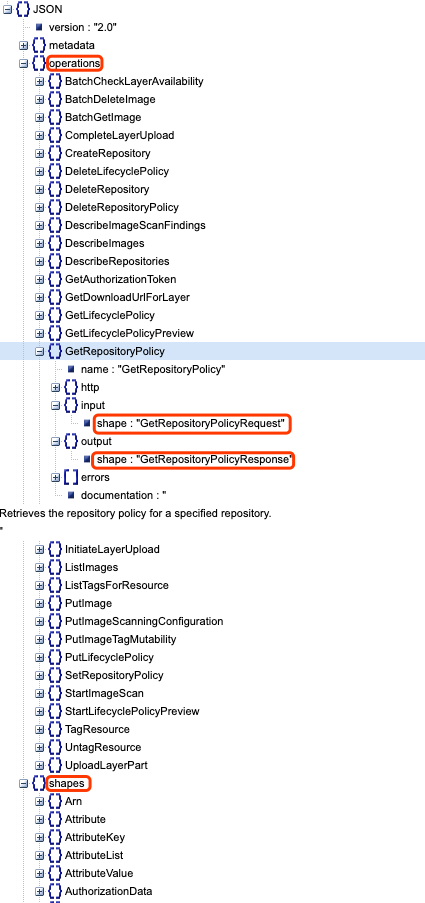
As you can see, each operation has four members: http, input, output, and errors, and each input and output has a shape. You can find the shapes down below:

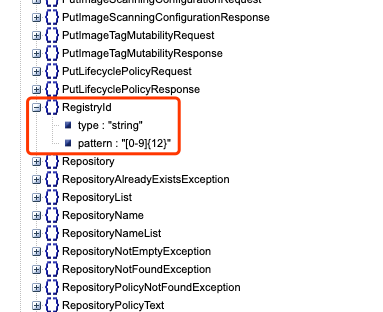
Each shape has two members: type and members. type is much like a data type, is it a string, number, or object. members include the arguments you pass to the API call, and each member has its own shape, making it a nested structure until a shape that has primitive data type is met, such as:
Following are some screenshots I made to better illustrate the whole process. All screenshots are made in VSCode.
When you create the service client, a class is created with the passed _loader that loads _service_model of that service.
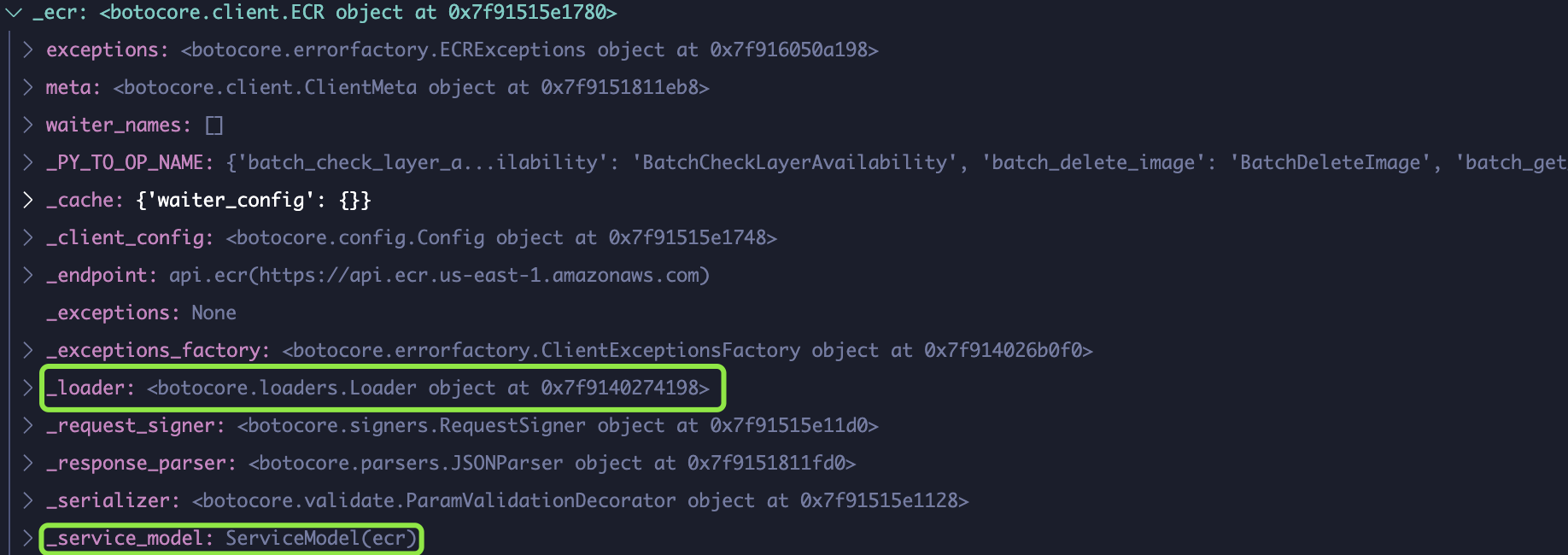
Operations and shapes are stored in _service_model.
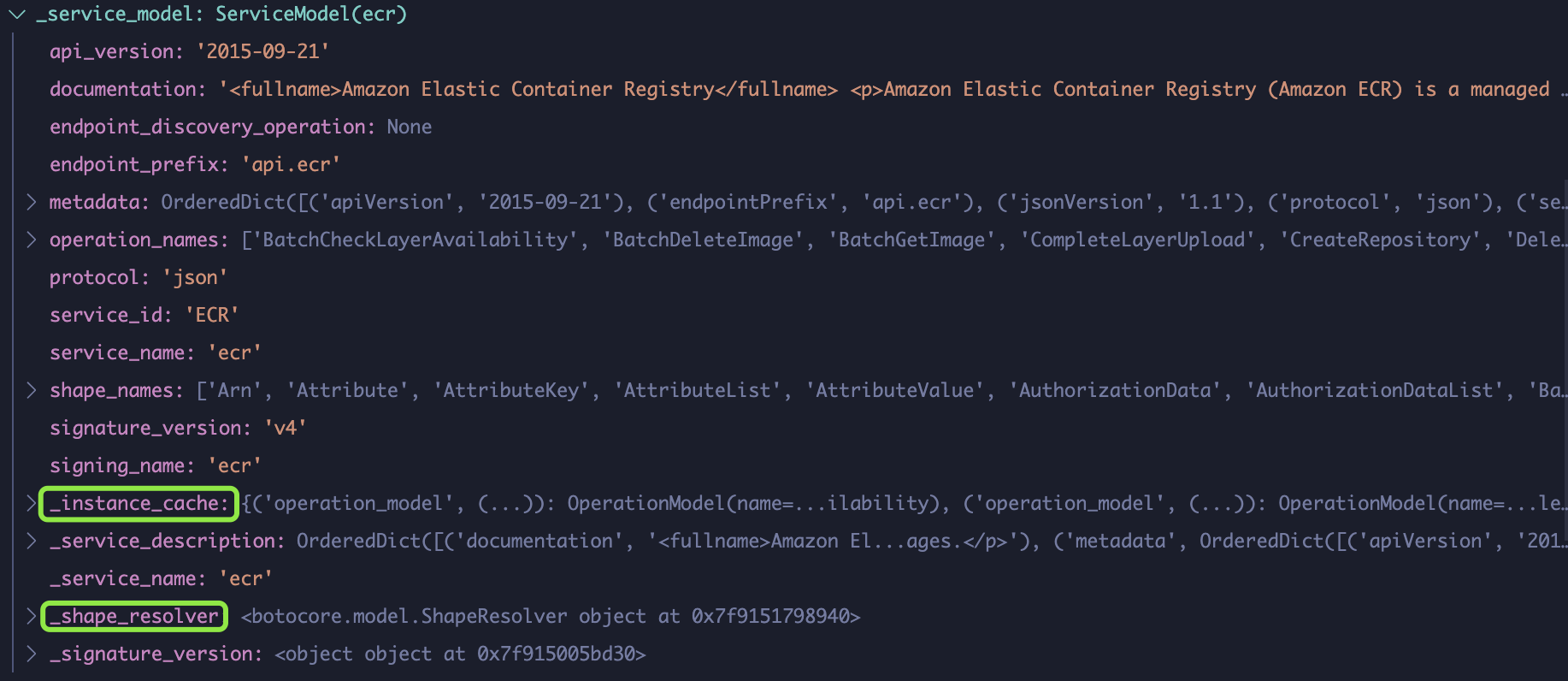
Operations.
Shapes.
Conclusion
In short, the AWS boto3 library dynamically generates classes and loads service model from a json file to create API methods.
However, why they do it this way remains a question for me. At first thought, I figured they might use the same JSON model to support all sdks, but then I found that’s not the case (check out DescribeRepositories API for Go and Java), then I thought maybe supporting both python2 and python3 for a big library is such a pain in the ass that they’d rather put all service models in standardized json? Or they explicitly want to make the library harder for people to read and break so they gain advantages over developers? I surely don’t want to maintain such a codebase if I don’t have to.
Emm… But what do I know?